A personalized Retrieval-Augmented Generation (RAG) system gives you an AI assistant that focuses on your specific work rather than the entire internet. Instead of relying on cloud models trained on billions of broad documents, a personalized RAG system uses only the sources you select—research papers, documentation, transcripts, or creative drafts.[3][5][6]
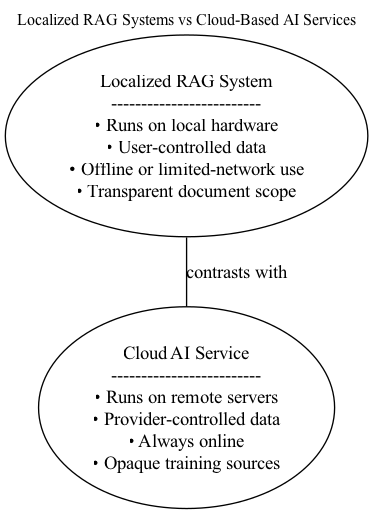
Running the system on your own hardware ensures that sensitive material never leaves your device. No external uploads, no vendor data collection, and no reliance on third-party APIs.[14] This gives you complete control over how your documents and models are stored and used.
Public LLMs are designed for broad audiences. A localized RAG system reads only the documents you choose and generates answers grounded in those sources. The result is precise, domain-specific output rather than generalized responses.[3][10][12]
Small local models use significantly less energy than large cloud-hosted models.[14] Each cloud request activates remote servers and network resources, while local models run on power your computer already draws. Reusing embeddings and a saved index further reduces unnecessary recomputation and long-term energy use.[3]
Small‑scale localized AI models raise important technological and societal questions, making them a meaningful contemporary tech issue. As AI becomes woven into education, research, creative work, and daily tasks, most people rely on cloud‑based systems that require constant data sharing. Localized RAG systems challenge this pattern by giving individuals direct control over computation, storage, and the knowledge their AI relies on. This shift encourages users to think critically about how AI systems are built, configured, and aligned with personal or project‑specific needs.
The move toward personal, user‑controlled AI has broader implications. It redistributes agency by allowing individuals—not only large companies—to shape how AI supports their work. At the same time, it introduces new responsibilities: users must understand system limitations, maintain their own setups, and ensure their data is handled ethically. Growing interest in localized AI also pushes discussions about sustainability forward, especially as people look for alternatives to energy‑intensive models running in large data centers.
Importantly, localized AI is not a replacement for large foundation models. Cloud systems still offer unmatched scale, multilingual reach, and general-purpose reasoning. The real issue is how these large systems should operate: with stronger privacy protections, clearer data practices, and sustainable resource usage. Concerns such as data centers operating in drought-prone regions illustrate why these questions matter. Localized AI complements large models by empowering individuals while preserving the value of centralized, high‑capacity systems.
Despite their advantages, small-scale localized RAG models have several limitations that are important to consider. Computational resource constraints on local hardware can limit model complexity and performance, which may affect the quality and speed of generated outputs. These models can also experience hallucinations—where the system generates plausible but incorrect information— a problem made more noticeable when training data is narrow or limited.[7][8][6]
Ethical considerations also come up, such as the risk of embedding biases from the chosen data, or missing important information because the dataset is small. Accessibility can be an issue, since building and maintaining these systems may require technical skills that not all users have. Reproducibility of results may also be difficult, since local environments, data updates, and model settings can vary, making validation and collaborative research more challenging.[8]
Addressing these challenges requires ongoing research into model robustness, clear evaluation methods, and user-friendly tools that make localized RAG systems accessible while keeping their benefits.
The following sections provide a comprehensive walkthrough for constructing a fully local retrieval-augmented generation system—from raw data to operational AI assistant:
Upon completion, readers will have acquired the knowledge to develop a self-contained, energy-efficient AI system that learns from domain-specific data and operates entirely on local hardware.[3][4][5][8]

For readers who want to move from orientation to hands-on understanding, the following resources are especially clear, practical, and beginner-friendly. Each offers a different entry point into retrieval-augmented generation without requiring deep theoretical background.
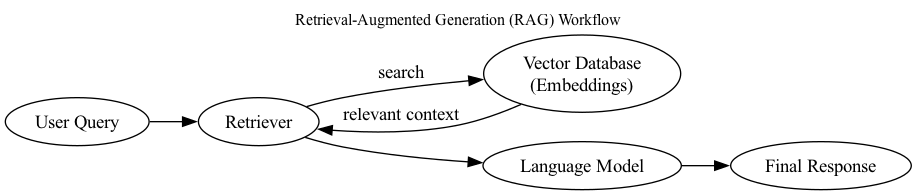
Building a RAG system begins with collecting and organizing your documents into clean, machine‑readable text. Consistent formatting improves chunking accuracy and prevents errors in later steps. Removing noise—duplicate headers, stray symbols, or irrelevant metadata—ensures the model has a clear foundation for understanding your material. [10][12]
Clean preparation matters: poor structure leads to weak embeddings and inaccurate retrieval. DigitAI, for example, required removing TEI metadata and restructuring content so that the model received only meaningful text. Careful documentation of preprocessing choices also supports reproducibility.
Next, large documents are broken into “chunks” that capture meaningful units of thought. Chunks that are too large mix topics; chunks that are too small lose context. Most projects perform well with sections of 300–600 words and slight overlaps. [3][5][12]
Chunking makes it possible for the system to compare ideas across your dataset. Humanities datasets often benefit from concept‑aligned chunk boundaries. DigitAI aligned its chunks with TEI rule sections, improving retrieval accuracy at the rule level.
Each chunk is converted into a numerical vector by your embedding model and stored in a vector database. These vectors capture meaning in a mathematical form, enabling fast similarity comparisons. [7][8]
High‑quality embeddings produce higher‑quality retrieval. DigitAI uses BGE‑M3 due to its semantic accuracy and stability with academic material. Choosing the right embedding model directly affects how the system interprets relationships between concepts.
A vector index must be built to allow fast searching. Saving this index means you can reuse embeddings without regenerating them, reducing both time and energy consumption. [15][3]
Indexing transforms your vector store into a structured, searchable system. DigitAI uses FAISS to achieve near‑instant lookups on modest hardware. Selecting an indexing strategy—flat, IVF, or HNSW—depends on dataset size, but even simple configurations work well for personal projects.
After retrieving the top‑ranked chunks, the system passes them to a language model, which generates an answer grounded in your documents. This step connects your dataset to the model’s reasoning. [7][8][15]
Reliable retrieval keeps the system anchored to factual information instead of relying on the model's internal training. DigitAI sends FAISS‑ranked TEI rules to the LLM to ensure domain‑accurate output.
The final step builds a structured prompt that includes the retrieved context. Clear prompting significantly reduces hallucinations and keeps the model focused on your text. [6][7][8]
DigitAI uses structured prompts that cite retrieved TEI rules before generating explanations, helping the model behave like a grounded tutor instead of an unconstrained generator.
An embedding model converts text into a high-dimensional vector that represents its meaning. These vectors allow the system to measure semantic similarity between documents and queries. Retrieval quality depends heavily on how well embeddings capture relationships between ideas. [7][8][5]
Technical definition: Embeddings typically exist in 384–1024‑dimensional vector spaces. Systems evaluate similarity using cosine similarity or dot‑product scoring; cosine similarity is preferred in RAG because it compares direction rather than magnitude, making it ideal for meaning‑based comparison.
Beginner note: Think of embeddings as “meaning fingerprints”—two texts with similar meaning produce similar fingerprints.
Advanced note: Models such as BGE‑M3 use multi‑task training (contrastive, classification, and instruction objectives) to stabilize semantic similarity across varied datasets, making them well suited for personal RAG systems.
A vector store is a database built for fast similarity search over embeddings. Unlike traditional databases that organize information by words or fields, vector stores operate on numerical meaning representations. [15][3]
Technical definition: Vector stores use indexing algorithms such as FAISS Flat, IVF, HNSW, or Product Quantization to reduce search complexity and support millisecond‑scale nearest‑neighbor lookups—even in large collections.
User-friendly explanation: A vector store acts like a librarian who organizes documents by meaning rather than alphabet.
Common choices:
• FAISS — fastest and most stable for local setups. [15]
• Chroma — simple Python integration; good for beginners. [15]
• Milvus — scalable but heavier to run.
• HNSWLib / Annoy — lightweight approximate‑search options.
For hobbyists and personal projects, FAISS remains the most reliable option.
A language model takes the retrieved chunks and generates a coherent answer grounded in the provided evidence. The LLM’s reasoning ability determines how well it integrates retrieved material and avoids hallucinations. [16][17][18]
Technical definition: LLMs use transformer‑based self‑attention to predict tokens. When provided with retrieval context, they shift from open‑ended generation to constrained, evidence‑guided reasoning.
Beginner note: The LLM is the “writer” of the system—it uses the retrieved chunks as research notes.
Model options:
• Qwen 2.5 (7B–14B) — excellent reasoning; highly adaptable. [1]
• Mistral 7B — efficient and fast on low‑VRAM systems. [1]
• Gemma 2 (9B) — stable and accurate; great grounding. [1]
• LLaMA 3 (8B) — strong general‑purpose performance. [1]
Retrieval narrows the information space to the most relevant documents, while the LLM synthesizes those documents into a final answer. This pairing compensates for standalone LLM weaknesses—particularly hallucination and outdated parametric memory. [7][8]
Technical detail: Combining embeddings, retrieval, and generation forms a “bounded‑context reasoning loop.” The LLLM becomes an interpreter of curated data rather than an improviser.
Why this is powerful: Grounding lets small, inexpensive models outperform larger general‑purpose LLMs on domain‑specific tasks by anchoring output directly in user‑selected knowledge.
Choosing the right components determines how accurate, responsive, and efficient your local RAG system will be. For individuals and hobbyists, the ideal setup delivers strong semantic understanding while remaining light enough to run on consumer hardware. This section outlines practical, well-supported options for embedding models, vector stores, and local LLMs, explaining the tradeoffs behind each choice. [7][8][5]
Embedding models define how your system represents meaning in vector form. High‑quality embeddings improve retrieval by placing semantically related chunks closer together in vector space. The stronger the embedding model, the more precisely the system can evaluate conceptual similarity. [7][8][5]
Definition (Beginner): An embedding model turns text into a numerical “meaning vector,” letting the system compare ideas mathematically.
BGE‑M3 / BGE‑Small: Exceptional multilingual semantic accuracy; efficient on CPUs and modest GPUs.
Best for: high‑quality retrieval in most personal systems. [1]
all‑MiniLM‑L6: Extremely lightweight and fast; English‑only.
Best for: older laptops and minimal‑resource setups. [5][12]
E5 Models: Trained for ranking relevance; excel in QA‑style retrieval.
Best for: precise academic or analytical datasets. [5][8]
Instructor Models: Tuned for representing instructions and rule‑based materials.
Best for: conceptual or procedural texts. [5]
Advanced note: BGE‑M3’s multitask training (contrastive, classification, and instruction tuning) produces especially stable similarity clustering for domain‑specific work.
The vector store determines how quickly and accurately the system retrieves relevant chunks. For local builds, users benefit most from tools that combine speed, simplicity, and reliability. [15][3]
Definition (Beginner): A vector store is a database for embeddings. When you ask a question, it finds the closest matching chunk.
FAISS: Industry‑standard library for similarity search; supports exact and approximate indexing.
Best for: nearly all personal RAG systems. [15][13]
Chroma: Beginner‑friendly, pure Python, minimal configuration.
Best for: rapid prototyping and straightforward workflows. [15]
Annoy / HNSWLib: Lightweight approximate nearest‑neighbor tools.
Best for: small datasets or limited‑memory environments. [15]
Advanced note: FAISS Flat performs exact search and is ideal for small–medium local datasets. IVF and HNSW structures are helpful only for much larger collections.
The LLM synthesizes retrieved chunks into fluent, grounded responses. Thanks to retrieval anchoring, small to mid‑sized open‑source models can achieve high accuracy without the compute demands of larger models. [16][17][18]
Definition (Beginner): The LLM is the “writer” of your system—it uses retrieved text as research material.
Qwen 2.5 (7B–14B): Strong reasoning, excellent grounding, multilingual.
Best for: high‑quality generation on everyday hardware. [1]
Mistral 7B: Fast and efficient.
Best for: low‑VRAM systems and speed‑critical tasks. [1]
Gemma 2 (9B): Accurate and stable.
Best for: precision‑focused work. [1]
LLaMA 3 (8B): Balanced, versatile general‑purpose model.
Best for: broad and creative applications. [1]
Advanced note: Quantizing models (4‑bit or 8‑bit) allows them to run on limited GPUs or even CPUs, making high‑quality local AI accessible to hobbyists.
For most individuals building a personal RAG system, this configuration provides the strongest balance of simplicity, accuracy, and performance:
Together, these tools create a stable, high‑quality RAG workflow accessible to hobbyists, students, and solo researchers.
This section outlines the complete workflow for building a local RAG system. Each step introduces both the conceptual reasoning and practical techniques required for a functional, efficient pipeline. The goal is to support beginners while offering enough depth for experienced hobbyists. [3][4][5][8]
Gather all relevant sources—articles, manuals, transcripts, notes—and convert them into clean, machine‑readable text. Consistency is crucial: irregular formatting, stray markup, or repeated headers can interfere with chunking and embedding. [10][12]
Definition (Beginner): Machine‑readable text is text the computer can interpret reliably—no broken formatting or inconsistent structure.
Advanced guidance: Normalize whitespace, clean metadata, and standardize punctuation. These refinements increase vector clarity and reduce retrieval noise.
Chunking divides large documents into coherent units of meaning. Chunks should capture complete concepts, not arbitrary lengths. Overlapping chunks (10–15%) preserves context between sections. [3][5][12]
Beginner note: Chunks act like short passages your system can search through.
Advanced note: Optimal chunk size depends on context‑window limits and conceptual density. Technical material often benefits from smaller, semantically aligned chunks.
Each chunk is fed into your embedding model, producing a numerical representation of meaning. These embeddings let the system compare chunks mathematically. [7][8]
Practical workflow:
• Embed chunks once per dataset update.
• Store chunk IDs, titles, and metadata.
• Cache embeddings so they don’t need recomputation.
Advanced note: Higher‑dimensional embeddings (e.g., 1024‑D) offer better meaning separation at the cost of slightly more storage.
Load embeddings into your vector store and build an index. Without indexing, the system would need to compare every embedding manually, slowing search substantially. [15][3]
Beginner note: An index is the structure that enables fast, accurate similarity search.
Advanced note: For personal datasets, FAISS Flat (exact search) is typically ideal. IVF and HNSW indexes are useful mainly for very large datasets.
When a user issues a query, the system embeds the question and compares it against your indexed embeddings. The closest matches—ranked by semantic similarity—form the retrieval set. [7][8][15]
Technical detail: Retrieval quality depends on embedding strength, chunking strategy, and indexing method. Tweaking any of these factors affects result precision.
Practical tip: Retrieving 3–10 chunks typically balances context coverage and noise reduction.
Construct a prompt that includes both the user’s question and the retrieved chunks. Clear prompt structure anchors the LLM to your sources, reducing hallucinations and maintaining domain accuracy. [6][7][8]
Beginner note: The prompt is simply instructions plus the retrieved evidence.
Advanced note: Effective prompts often include system instructions, citation rules, safety constraints, and explicit directions to rely solely on retrieved material.
When you add new documents or make changes, you’ll need to regenerate embeddings to keep the system accurate. In practice, updating embeddings regularly makes sure your AI reflects the latest information and research. [10][12]
To check output quality, see if the retrieved passages really support the answer. Using metrics like precision, recall, and human review will help you spot areas for improvement. [7][8][9]
For better performance, consider adjusting chunk size, using GPU acceleration, or trying more efficient indexing methods. These changes can make your system more responsive and pleasant to use. [15][3]
Running models with minimal computational overhead saves energy and reduces heat. In many cases, lightweight models and reusing indices help create a more sustainable AI workflow. [14]
Adding more datasets can expand your AI’s knowledge base. When you bring in new data, remember to preprocess, chunk, and generate embeddings to keep quality consistent. [10][12]
Trying out different embedding and language models lets you compare accuracy, speed, and how well they fit your domain. In practice, benchmarking helps you find the best setup for your needs. [1][5]
Creating a user interface—like a command line tool, web dashboard, or chat app—makes the system more accessible. This helps non-technical users interact with your AI more easily. [18]
Documenting your methods, challenges, and outcomes supports reproducibility and collaboration. Sharing your findings also adds to the wider conversation on localized AI. [8][9]
This resource guide is supported by a public Zotero library that collects all cited materials along with additional readings for deeper exploration. Rather than summarizing every source, this guide highlights key ideas and points readers toward the most useful resources.
Public Zotero Library: DigitAI v2 – Localized AI & RAG Systems
The Zotero library is maintained as a living collection and may be updated as new research and tools emerge.
All diagrams in this guide were created by the author to illustrate localized retrieval-augmented generation workflows and system architectures.
This guide was developed through a combination of independent research, iterative drafting, and selective AI-assisted editing, with all content reviewed and revised by the author.